14.
Valutare l’usabilità
Sintesi del capitolo
Questo capitolo descrive le due tecniche più utilizzate per
valutare l’usabilità dei sistemi: le cosiddette valutazioni euristiche e i test
di usabilità. Nel primo caso, la valutazione è eseguita da esperti di usabilità,
con l’aiuto di regole più o meno dettagliate, che riflettono lo stato delle
conoscenze del settore. Si citano le euristiche di Nielsen, molto conosciute.
Nel secondo caso, i test sono effettuati da un campione di utenti, che
utilizzano il sistema in un ambiente controllato, sotto osservazione da parte
dei valutatori. I test di usabilità si possono classificare in formativi e
sommativi; in test di compito e di scenario. Il capitolo termina con una serie
di indicazioni pratiche per la preparazione e la esecuzione di un test di
usabilità, e per la preparazione del rapporto di valutazione.
Verifiche e convalide
Nel modello di progettazione e
sviluppo iterativi descritto nella Figura 3 del Capitolo 6, ad ogni ciclo di
iterazione si effettuano dei test di valutazione dell’ultimo prototipo
prodotto. Come specifica lo standard ISO 13407, “la valutazione è un passo
essenziale in una progettazione human-centred. All’inizio del progetto, l’obiettivo
principale sarà la raccolta di indicazioni per orientare le attività di
progettazione successive. Nelle fasi più avanzate, con la disponibilità di
prototipi più completi, sarà invece possibile quantificare il livello di
raggiungimento degli obiettivi dell’utente e dell’organizzazione. Dopo il
rilascio del sistema, sarà possibile monitorarne l’adeguatezza ai nuovi
contesti di utilizzo.”
I termini generici
“valutazione” o “test” possono denotare due attività molto diverse:
·
il
controllo che il prodotto sia congruente con quanto espresso nei documenti di
specifica dei requisiti. Per questo tipo di test si usa normalmente il termine verifica (verification);
· il controllo che il prodotto soddisfi effettivamente le esigenze per le quali è stato concepito. Per questo tipo di test si usa, invece, il termine convalida (validation).
Nel primo caso si tratta, come
si usa dire nella lingua inglese, di verificare che il gruppo di progetto “made
the things right”; nel secondo caso che “made the right things”. La differenza
fra verifica e convalida è sostanziale, perché non è detto che i documenti di
specifica dei requisiti esprimano sempre correttamente le esigenze che il
prodotto dovrebbe soddisfare. Infatti, l’estensore delle specifiche potrebbe
avere male interpretato le richieste degli stakeholder del prodotto, che
peraltro nel corso del progetto potrebbero cambiare.
Le attività di convalida sono
molto più difficili delle verifiche. Non si tratta, infatti, di controllare la
congruenza (o, come si dice, la tracciabilità)
fra le caratteristiche del prodotto e le indicazioni contenute nel documento
dei requisiti, ma di controllare che il prototipo soddisfi effettivamente le
esigenze espresse (o, a volte, ancora inespresse) del committente. Per questo,
la convalida non può essere condotta soltanto dal team di progetto, ma richiede
necessariamente il coinvolgimento dell’utente e degli altri stakeholder del
prodotto.
In questo libro ci occuperemo,
in particolare, delle attività di valutazione dell’usabilità, rimandando per
gli altri aspetti all’ampia letteratura esistente sul testing in generale. Per
compierle si possono impiegare diverse tecniche, che rientrano in due grandi
categorie:
·
Valutazioni effettuate da parte di esperti di
usabilità, senza alcun coinvolgimento dell’utente.
Queste valutazioni prendono il nome di ispezioni
(inspection). Le più note sono le
cosiddette valutazioni euristiche (euristic evaluation).
· Valutazioni effettuate con il coinvolgimento dell’utente.
Sono le più importanti e le più utilizzate. Fra queste, nel seguito saranno descritti i test di usabilità (usability test).
Valutazioni euristiche
L’aggettivo euristico si usa, in matematica, per
denotare un procedimento non rigoroso che consente di prevedere o rendere
plausibile un determinato risultato, che in un secondo tempo dovrà essere
controllato e convalidato con metodi rigorosi. Nell’ingegneria dell’usabilità,
si chiamano euristiche quelle valutazioni di usabilità effettuate da esperti,
analizzando sistematicamente il comportamento di un sistema e verificandone la
conformità a specifiche “regole d’oro” (chiamate, appunto, euristiche), derivanti
da principi o linee guida generalmente accettati. In pratica, per eseguire una
valutazione euristica, l’esperto di usabilità dovrebbe considerare una regola
euristica alla volta, ed esaminare dettagliatamente le funzioni del sistema,
per verificarne la conformità.
Le euristiche impiegate sono
diverse. In letteratura se ne trovano alcune costituite da centinaia di regole
dettagliate. È evidente che valutare un sistema in base a una tale quantità di
regole risulta impraticabile. Si preferisce quindi, più spesso, utilizzare
euristiche costituite da pochi principi guida generali. Fra queste, sono molto
note le euristiche di Nielsen, costituite da dieci regole che, sebbene molto
generali, permettono al valutatore di inquadrare i problemi rilevati in
categorie bene individuate.
Le dieci euristiche di Nielsen,
spiegate con le sue stesse parole, sono le seguenti[1]:
1. Visibilità dello stato del sistema
Il sistema dovrebbe sempre informare gli utenti su ciò che sta accadendo, mediante feedback appropriati in un tempo ragionevole.
2. Corrispondenza fra il mondo reale e il sistema
Il sistema dovrebbe parlare il linguaggio dell’utente, con parole, frasi e concetti familiari all’utente, piuttosto che termini orientati al sistema. Seguire le convenzioni del mondo reale, facendo apparire le informazioni secondo un ordine logico e naturale.
3. Libertà e controllo da parte degli utenti
Gli utenti spesso selezionano delle funzioni del sistema per errore e hanno bisogno di una “uscita di emergenza” segnalata con chiarezza per uscire da uno stato non desiderato senza dover passare attraverso un lungo dialogo. Fornire all’utente le funzioni di undo e redo.
4. Consistenza e standard
Gli utenti non dovrebbero aver bisogno di chiedersi se parole, situazioni o azioni differenti hanno lo stesso significato. Seguire le convenzioni della piattaforma di calcolo utilizzata.
5. Prevenzione degli errori
Ancora meglio di buoni messaggi di errore è un’attenta progettazione che eviti innanzitutto l’insorgere del problema. Eliminare le situazioni che possono provocare errori da parte dell’utente, e chiedergli conferma prima di eseguire le azioni richieste.
6. Riconoscere piuttosto che ricordare
Minimizzare il ricorso alla memoria dell’utente, rendendo visibili gli oggetti, le azioni e le opzioni. L’utente non dovrebbe aver bisogno di ricordare delle informazioni, nel passare da una fase del dialogo a un’altra. Le istruzioni per l’uso del sistema dovrebbero essere visibili o facilmente recuperabili quando servono.
7. Flessibilità ed efficienza d’uso
Acceleratori – invisibili all’utente novizio – possono spesso rendere veloce l’interazione dell’utente esperto, in modo che il sistema possa soddisfare sia l’utente esperto sia quello inesperto. Permettere all’utente di personalizzare le azioni frequenti.
8. Design minimalista ed estetico
I dialoghi non dovrebbero contenere informazioni irrilevanti o necessarie solo di rado. Ogni informazione aggiuntiva in un dialogo compete con le unità di informazione rilevanti e diminuisce la loro visibilità relativa.
9. Aiutare gli utenti a riconoscere gli errori, diagnosticarli e correggerli
I messaggi di errore dovrebbero essere espressi in linguaggio semplice (senza codici), indicare il problema con precisione e suggerire una soluzione in modo costruttivo.
10. Guida e documentazione
Anche se è preferibile che il sistema sia utilizzabile senza documentazione, può essere necessario fornire aiuto e documentazione. Ogni tale informazione dovrebbe essere facilmente raggiungibile, focalizzata sul compito dell’utente, e dovrebbe elencare i passi concreti da fare, senza essere troppo ampia.
La Figura
1 mostra
una possibile corrispondenza fra le euristiche di Nielsen e le regole dell’ISO
9241 descritte nel Capitolo 10. Si noti che più euristiche possono derivare da
uno stesso principio e, d’altro canto, più principi possono giustificare una
stessa euristica. Per esempio, l’euristica “flessibilità ed efficienza d’uso”
può essere associata anche al principio “adeguatezza all’individualizzazione”.
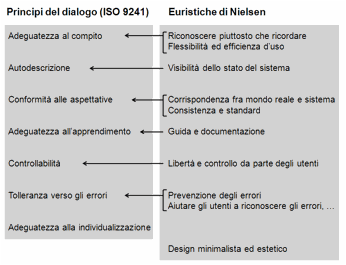
Figura 1. Confronto fra i principi del dialogo dell’ISO 9241e le euristiche di Nielsen
La valutazione euristica ha il
vantaggio di essere relativamente poco costosa. Tuttavia fornisce risultati piuttosto
soggettivi. Quanto più le euristiche sono generali, tanto più il risultato
della valutazione dipenderà dall’esperienza, dalla sensibilità e, a volte,
dalle preferenze personali del valutatore. Le esperienze condotte in molti
progetti hanno mostrato che valutatori diversi tendono a trovare problemi
diversi. La Figura
2 mostra
i risultati della valutazione euristica di un sistema bancario effettuata da 19
valutatori, descritta dallo stesso Nielsen.[2]
Il diagramma riporta in verticale i valutatori, e in orizzontale i 16 problemi
di usabilità da questi individuati. Ogni quadratino nero indica un problema segnalato
da un valutatore. I problemi sono ordinati lungo l’asse orizzontale: più sono a
destra, più valutatori li hanno individuati. La figura mostra chiaramente che i
diversi valutatori hanno trovato problemi diversi. Nessun problema è stato segnalato
da tutti i valutatori, e solo 4 sono stati segnalati da più della metà dei
valutatori. Alcuni
problemi “facili” da trovare (quelli sulla destra) sono stati individuati da
quasi tutti i valutatori, altri (quelli sulla sinistra) soltanto da pochi.
Infine, i valutatori che hanno segnalato alcuni dei problemi più difficili da
scoprire, non ne hanno invece segnalati alcuni che sono stati individuati da
molti valutatori.
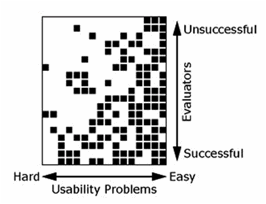
Figura 2. Risultati di una valutazione euristica di un sistema bancario (http://www.useit.com)
In sintesi, con la valutazione
euristica è possibile ottenere buoni risultati solo impiegando più valutatori
sullo stesso progetto, che analizzino separatamente il sistema senza comunicare
fra loro. In ogni caso, questa tecnica non garantisce che vengano rilevati
tutti i problemi di usabilità, e può capitare che vengano segnalati problemi
che, in realtà, non esistono. Ciò è dovuto al fatto che i valutatori possono
avere delle preferenze personali su come determinate funzioni del sistema
debbano essere sviluppate, e non è detto che queste corrispondano a criteri
oggettivamente verificabili. È anche evidente che i risultati saranno tanto più
affidabili quanto più i valutatori saranno esperti nel particolare ambito in
esame. Di conseguenza, la valutazione euristica può aggiungersi, ma non
sostituirsi ai test con gli utenti, che devono comunque essere condotti. I due tipi di valutazioni sono complementari, e possono dare
risultati diversi (Figura 3).
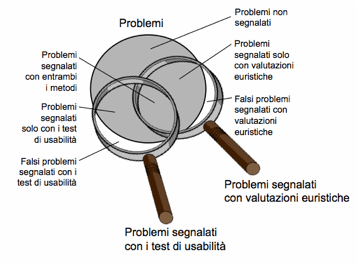
Figura 3. a) Risultati della valutazione euristica; b) confronto fra valutazione euristica e test di usabilità
Test di usabilità
Un test di usabilità consiste
nel far eseguire a un gruppo di utenti dei compiti tipici di utilizzo del
sistema in un ambiente controllato. Si sceglie un campione di utenti che sia
rappresentativo della categoria di utenti cui il sistema si rivolge, e si
chiede a tutti di svolgere, separatamente, gli stessi compiti. Chi conduce il
test osserva e analizza il loro comportamento per comprendere se, dove e perché
essi hanno incontrato delle difficoltà. Il test coinvolge, oltre all’utente che
prova il sistema, almeno due altre persone: un facilitatore, che ha il compito di gestire la “regia” della prova,
e uno o più osservatori, che
assistono al test, annotando i comportamenti dell’utente che ritengono
significativi. Il ruolo degli osservatori è critico: essi dovrebbero conoscere
bene il sistema, e avere eseguito personalmente i compiti chiesti agli utenti.
Solo in questo modo saranno in grado di interpretarne e valutarne correttamente
i comportamenti. Facilitatori e osservatori potranno essere degli esperti di
usabilità, oppure dei membri del team di progetto, a seconda dei casi.
Quando si usino prototipi di
carta o tecniche con il mago di Oz (vedi Capitolo 9), servirà una terza
persona, con il compito di simulare il sistema. Come abbiamo già osservato, si
tratta di un compito piuttosto impegnativo, che richiede preparazione e
attenzione; pertanto, non potrà essere svolto né da chi coordina il test né da
chi ne osserva lo svolgimento. A simulare il sistema sarà molto spesso un
progettista, che conosca ne bene il funzionamento previsto.
Un test di usabilità ha lo
scopo di ricavare indicazioni concrete per il miglioramento del sistema. Chi lo
conduce dovrà esaminare in dettaglio le operazioni svolte dagli utenti per
capire dove nascono le difficoltà, da che cosa sono causate e in quale modo
possano essere rimosse. Per questo, è molto utile la cosiddetta tecnica del
“pensare ad alta voce“ (think aloud), che consiste nel chiedere
all’utente di esprimere a voce alta ciò che pensa mentre compie le varie
operazioni. Questo è molto utile, perché permette agli osservatori di raccogliere
informazioni sulle strategie messe in atto dall’utente nell’esecuzione dei
compiti, e sulle difficoltà che egli incontra durante il test.[3]
L’analisi del comportamento
degli utenti non può essere condotta in tempo reale durante lo svolgimento del
test, ma deve essere compiuta dopo, con la necessaria tranquillità. Anche se
l’utente esprime ad alta voce, durante la prova, le difficoltà che sperimenta,
le cause di queste difficoltà possono non essere evidenti. Per identificarle, e
comprendere come possano essere rimosse, sarà necessario riesaminare con
attenzione la sequenza di azioni eseguite dall’utente. Durante il test,
l’osservatore dovrà quindi prendere appunti, registrando le situazioni in cui
l’utente manifesta incertezza o commette degli errori. Questi appunti saranno
riesaminati in seguito, per individuare le cause del problema e studiare le
correzioni più opportune.
Se possibile, è preferibile
eseguire una registrazione (audio e video) della sessione di test, per rivedere
in seguito tutto ciò che è avvenuto durante la prova. La tecnica più comune
consiste nel riprendere con una telecamera il viso dell’utente mentre esegue il
test, registrando contemporaneamente le sue parole e, con un’altra telecamera,
il sistema. Le due registrazioni dovranno poi essere viste in modo
sincronizzato: spesso le espressioni del viso dell’utente sono altrettanto
rivelatrici delle sue parole e delle sue azioni. Le Figura
4 e Figura
5 sono
tratte, rispettivamente, dalla registrazione di un test con un prototipo di
carta e con un prototipo PowerPoint per un’applicazione iPhone. In entrambe,
sulla sinistra appare il viso dell’utente, sulla destra le operazioni che
compie sul sistema. Nella prima figura, sono stati inseriti in
sovraimpressione, per comodità, i nomi dei compiti in esecuzione (“Leggi
l’avviso più recente”).

Figura 4. Registrazione di un test di usabilità con prototipo di carta
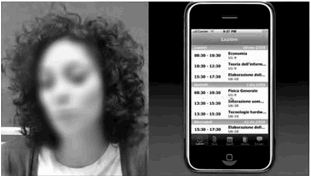
Figura 5. Registrazione di un test d’usabilità per un’applicazione su iPhone
Nel caso di sistemi eseguiti al
computer, tutto questo si può fare, molto semplicemente, con una sola webcam
che riprenda il viso dell’utente, un microfono e un programma in esecuzione
sullo stesso computer usato per il test, che registri le immagini che appaiono
sul video, in modo sincronizzato con le registrazioni audio e video. Tali
programmi (ne esistono anche di gratuiti) permettono poi di esaminare in
dettaglio, per così dire alla moviola, le azioni effettuate dall’utente e
metterle in corrispondenza con le espressioni del viso e le parole pronunciate. La Figura
6 mostra
una immagine dalla registrazione di un test di un sito web.
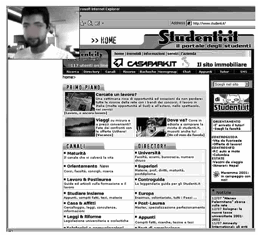
Figura 6. Registrazione di un test di usabilità con un programma apposito
Fino a qualche anno fa era
diffusa la convinzione che per fare un buon test di usabilità fosse
indispensabile usare un laboratorio appositamente attrezzato (usability lab). Esso è costituito da due stanze contigue: una per l’utente
che prova e una per gli osservatori (Figura
7).
Nella prima, l’utente esegue il test da solo; nella seconda, il facilitatore e
gli osservatori lo possono vedere (non visti) attraverso un finto specchio, che
permette a chi si trova nella sala di osservazione di vedere l’interno della
sala prove, ma non viceversa. La sala osservazione contiene inoltre tutti gli
apparati necessari per controllare la registrazione audio e video delle prove:
una vera e propria sala di regia.
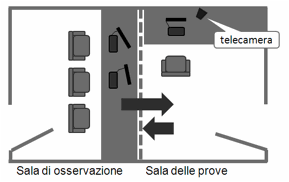
Laboratori di questo tipo sono
piuttosto costosi, e sono usati dalle organizzazioni che devono condurre molti
test, in modo professionale. Tuttavia, per condurre dei buoni test di usabilità
non è indispensabile disporre di una struttura
di questo tipo, e ci si può organizzare in modo molto più semplice. Oggi quasi
ogni computer è dotato di una webcam integrata e, come abbiamo detto, esistono
numerosi pacchetti software che gestiscono la registrazione senza che siano
necessarie apparecchiature e competenze particolari. Utente, facilitatore e
osservatori si possono semplicemente disporre attorno a un tavolo, come in Figura 8.
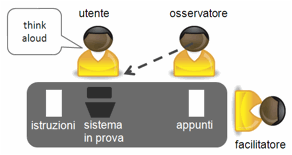
Figura 8. Test di usabilità informale
Se si
dispone di una stanza riservata dove condurre il test, tanto meglio, ma neanche
questo è indispensabile: la Figura 9
mostra un test di usabilità condotto con successo in un laboratorio
universitario molto affollato. Ovviamente, in una situazione di questo tipo
sarà più difficile fare seguire il test da più osservatori: la logistica non lo
consente. In effetti, uno dei principali vantaggi di uno usability lab come
quello di Figura 7
è che si può fare assistere alle prove anche qualche progettista. Vedere con i
propri occhi come l’utente si blocchi tentando di usare il sistema, e sentirne
i commenti – a volte esasperati - può rivelarsi veramente molto
istruttivo.

Figura 9. Test di usabilità di fortuna
Test formativi e test sommativi
Vedremo in dettaglio, più oltre, come un test di usabilità debba essere organizzato e condotto. Per il momento, segnaliamo che i test di usabilità possono essere classificati, in funzione dei loro obiettivi, in due grandi categorie: test formativi (formative) e test sommativi (summative).
I primi sono utilizzati
durante il ciclo iterativo di progettazione, per sottoporre i vari prototipi a
prove d’uso con gli utenti, allo scopo di identificarne i difetti e migliorarne
l’usabilità. Si chiamano formativi perché, appunto, contribuiscono a “dare
forma” al prodotto: il loro scopo è individuare il maggior numero possibile di
problemi. Essi sono particolarmente utili nelle fasi iniziali della
progettazione, quando il design concept è appena abbozzato. È spesso
conveniente eseguire questi test in modo rapido e approssimativo (quick & dirty), facendo esercitare a un piccolo numero di utenti le
funzionalità principali del sistema. Questo perché nelle fasi iniziali del
progetto, quando il design concept è appena abbozzato, i test mettono in luce
rapidamente i difetti macroscopici, che richiedono una parziale (o totale)
riprogettazione dell’interfaccia. Quindi non conviene andare troppo per il
sottile: si sprecherebbe del tempo provando “a tappeto” funzioni che, nella
riprogettazione, saranno probabilmente modificate.
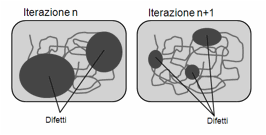
Inoltre, si verifica
spesso un effetto di mascheramento:
ogni problema di usabilità nel quale incappiamo monopolizza, per così dire, la
nostra attenzione e ci impedisce spesso di vederne altri, soprattutto se di più
lieve entità. Li scopriremo all’iterazione successiva, quando il problema
iniziale sarà stato rimosso (Figura 10). Quindi si prova in fretta, si modifica
rapidamente il prototipo eliminando i difetti più evidenti, e si prova ancora,
e così via. Per il primo test di un prototipo iniziale di carta, 2-3 utenti
sono in genere sufficienti.
Jakob Nielsen ha
introdotto il termine discount usability (usabilità scontata) per indicare queste tecniche, rapide, poco costose e non troppo
sistematiche per individuare i problemi di usabilità. Già in un articolo del
1993[4] aveva osservato che utilizzare molti utenti nei test di
usabilità è inutilmente costoso, e che sono in genere sufficienti da 3 a 5
utenti per rilevare più del 75% dei problemi di usabilità in un sistema (Figura 11).
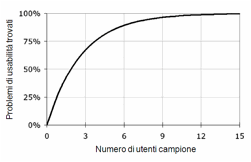
Figura 11. La “regola di Nielsen” per i test di usabilità (da www.useit.com)
Questa semplice
indicazione pratica (chiamata regola di
Nielsen) è stata in seguito criticata da diversi autori, che ne hanno
contestato la validità generale. Lo stesso Nielsen l’ha parzialmente modificata,
portando il numero suggerito di utenti a 5. In pratica, dice Nielsen, i primi 5
utenti metteranno in evidenza la maggior parte dei problemi di usabilità più
significativi: gli utenti successivi non farebbero altro che confermare gli
stessi risultati, aggiungendo ben poco di nuovo.
I test della seconda
categoria si chiamano sommativi. Il termine deriva dal verbo “sommare”, ed
indica una valutazione più complessiva del prodotto, al di fuori – o al
termine – del processo di progettazione e sviluppo. Sono test più
completi di quelli formativi, che non hanno lo scopo di fornire indicazioni ai
progettisti, ma di valutare in modo sistematico pregi e difetti del prodotto, o
sue particolari caratteristiche.[5] Sono di solito condotti quando il sistema è completamente
funzionante, per esempio per indicarne i punti deboli e valutare l’opportunità
di un redesign migliorativo. Oppure per confrontarne le caratteristiche con
quelle di sistemi concorrenti. Anche se non si possono dare regole fisse, un
test di usabilità ben strutturato, di tipo sommativo, coinvolge di solito un
numero maggiore di utenti, per esempio 10-15, o anche di più.
Qualunque sia la
strategia adottata, i soggetti da utilizzare nei test dovranno sempre essere
scelti con cura, affinché rappresentino utenti tipici. Per poter interpretare
correttamente l’esito di ciascun test, chi lo conduce dovrà conoscere, per
ciascun soggetto, il livello di esperienza nell’uso di sistemi analoghi a
quello in esame. Il suo profilo
dovrebbe essere classificato su due dimensioni: il livello di conoscenza del
dominio applicativo del sistema, e il livello di familiarità con la tecnologia utilizzata
(Figura 12).
Queste due dimensioni sono largamente indipendenti. Per esempio, nel test del
sito web di una compagnia aerea, alcuni utenti potrebbero avere una lunga
esperienza di viaggi in aereo, ma non avere mai fatto un acquisto online. La
conoscenza del profilo degli utenti impiegati nelle prove è indispensabile, per
interpretarne correttamente i risultati.
Nella scelta degli
utenti, si potranno scegliere rappresentanti di tutti i quadranti della figura,
o solo di alcuni, a seconda degli obiettivi del test e della natura del
sistema. In genere conviene scegliere utenti con caratteristiche diverse. In
tal modo, è probabile che essi affronteranno i compiti assegnati con strategie
differenti, esercitando aspetti diversi del sistema. In ogni caso, tutti gli
utenti dovrebbero avere almeno un potenziale interesse nelle funzioni svolte
dal sistema. Non ha
senso chiedere a chi non è mai salito su un aereo di prenotare un volo sul sito
di una compagnia aerea. Si rischierebbe di incontrare delle difficoltà che non
derivano dal sistema, ma dalla poca dimestichezza che l’utente ha con il
problema che gli è stato sottoposto. I risultati della prova ne saranno
probabilmente inquinati. È sbagliato, per “fare numero”, reclutare le persone
più facilmente disponibili, senza altri accertamenti: si devono proprio
selezionare dei potenziali clienti del sistema.

Figura 12. Le due dimensioni del profilo degli utenti
Naturalmente, gli utenti
per le prove non dovranno mai essere scelti all’interno del gruppo di progetto.
I progettisti conoscono troppo bene il sistema per fornirci delle indicazioni
significative. Anche se ci assicurassero che faranno il possibile per ignorare
quello che sanno e di “mettersi nei panni dell’utente”, le loro prove sarebbero
inevitabilmente poco attendibili.
Test di compito e test di scenario
Rispetto alle attività condotte dagli utenti durante le prove, i test di usabilità possono essere classificati in due grandi categorie: test di compito e test di scenario.
Nei test di compito, gli utenti
svolgono singoli compiti, che permettono di esercitare funzioni specifiche del
sistema. Per esempio, nel caso di un sito web di un supermercato:
Compito 1: Ricerca nel
catalogo dei prodotti una scatola di pomodori pelati da 500 grammi;
Compito 2: Comprane due,
pagando con la tua carta di credito;
Compito 3: Verifica lo stato
del tuo ordine precedente.
Questi test possono
essere eseguiti anche quando il sistema non è completamente sviluppato. Per
esempio, per eseguire la ricerca nel catalogo dei prodotti, non è necessario
che le funzioni per l’acquisto siano già disponibili. Essi sono tanto più utili
quanto più i compiti riflettono i casi d’uso reali del sistema. Un errore
frequente dei conduttori inesperti è quello di suggerire implicitamente agli
utenti le operazioni da eseguire, dando loro, in pratica, una serie di
istruzioni, invece che un problema da risolvere. L’utente deve, invece, essere
posto in situazioni simili a quelle in cui si troverà nell’uso reale del
sistema, quando dovrà decidere, da solo, che cosa fare. Se l’utente è troppo
guidato, i problemi di usabilità, anche se presenti, non emergeranno, e il test
non sarà di alcuna utilità. Per esempio, consideriamo la seguente
riformulazione dei due compiti dell’esempio precedente:
Compito 1: Registrati al
sistema, fornendo il tuo indirizzo di email e una password;
Compito 2: Entra nella
sezione per gli acquisti online e ricerca la sottosezione dei prodotti in
scatola;
Compito 3: Ricerca una
scatola di pomodori pelati da 500 gr e caricala nel carrello della spesa;
Compito 4: Conferma
l’acquisto fornendo questo indirizzo di consegna e questi dati per l’addebito
su carta di credito.
Procedendo in questo modo, daremmo all’utente troppe indicazioni sul
funzionamento del sistema, anche se in modo implicito. Per esempio, gli faremmo
sapere che, per comprare qualcosa, deve prima registrarsi, fornendo come
user-id il suo indirizzo di posta elettronica. Poi che esiste una sezione per
gli acquisti online, e che questa è organizzata in sottosezioni, una delle
quali riguarda i prodotti in scatola. Quindi che per comprare qualcosa bisogna
caricarlo nel carrello, e così via. Tutte queste informazioni non sono invece
disponibili all’utente in un contesto di acquisto reale, soprattutto se egli non
ha mai utilizzato un sistema simile. In definitiva, in un contesto reale
l’utente potrebbe incontrare delle difficoltà che in un test così formulato non
si presentano mai.
La seconda categoria è costituita dai test
di scenario. In questo caso, agli utenti viene indicato un
obiettivo da raggiungere attraverso una serie di compiti elementari, senza
indicarli esplicitamente. L’utente dovrà quindi impostare una propria strategia
di azione. Per un test più realistico, all’utente potrà essere indicato uno scenario
complessivo che definisca meglio il contesto in cui dovrà immaginare di
muoversi. Per esempio, per il sito del supermercato, lo scenario proposto agli
utenti potrebbe essere il seguente:
Domani
sera hai due amici a cena, ma non hai il tempo di andare al supermercato.
Decidi quindi di fare la spesa online, pagando con la tua carta di credito.
Collegati al sito e ordina gli ingredienti per una cena veloce e poco costosa,
ma simpatica.
Come si vede da questo
esempio, i test di scenario possono mettere alla prova l’utente (e il sistema)
in modo molto più impegnativo dei test di compito. In particolare, permettono
agli utenti di utilizzare il sistema in relazione alle proprie specifiche
necessità, preferenze e abitudini. Nello scenario indicato, gli utenti terranno
conto delle loro preferenze alimentari, e di quelle dei loro amici.
Utilizzeranno la loro carta di credito, e chiederanno la consegna al loro vero
indirizzo, verificando se questa potrà essere effettuata in tempo utile per la
cena. Così, la strategia che gli utenti seguiranno per raggiungere l’obiettivo
potrebbe essere molto diversa da quella prevista dai progettisti. Per questo
motivo, i test di scenario possono essere molto utili per individuare eventuali
carenze nell’impostazione della struttura complessiva dell’interazione, o
mancanze di funzionalità utili. Dunque, si dovrebbe cercare di anticipare, per
quanto è possibile, i test di scenario all’inizio del progetto, usando anche
prototipi parziali o a bassa fedeltà. I test di compito permettono, invece, una
verifica di usabilità più fine, perché localizzata a specifici casi d’uso.
Quindi possono essere più utili quando l’architettura funzionale del sistema
sia già ben consolidata, per provare l’usabilità di specifiche funzioni.
È indispensabile che le
istruzioni agli utenti (l’elenco dei compiti da svolgere o la descrizione degli
scenari) siano date per iscritto, nel modo più chiaro possibile. Solo in questo
modo tutti gli utenti partecipanti al test si troveranno nelle medesime
condizioni: le spiegazioni date a voce, inevitabilmente diverse di volta in
volta, potrebbero influenzare i partecipanti in modo differente, rendendo i
risultati dei test poco confrontabili.
Misure
Oltre all’osservazione
qualitativa dei comportamenti degli utenti, durante un test di usabilità è
utile raccogliere anche delle misure oggettive. Quelle più significative sono
il tempo impiegato da ogni utente per l’esecuzione di ciascun compito, e il tasso
di successo (success rate), cioè la
percentuale di compiti che ciascuno riesce a portare a termine.
Il calcolo del tasso di
successo può tener conto anche dei compiti eseguiti solo in parte. Si
consideri, per esempio, il test descritto in Figura 13,
in cui 4 utenti eseguono 6 compiti. Su 24 compiti, 9 sono stati portati a
termine (S), e 4 sono stati eseguiti solo in parte (P). Per i rimanenti, gli
utenti hanno fallito (F).

Figura 13. Sintesi risultati di un test di usabilità
In questo caso, il tasso
di successo potrebbe essere calcolato così:
Tasso di successo = (9 + (4 * 0,5)) / 24 = 46%
In questa formula, ogni
successo parziale è stato conteggiato, convenzionalmente, come la metà di un
successo pieno. Il risultato di questo calcolo ci dice che gli utenti non sono
riusciti a portare a termine più della metà dei compiti assegnati. Questo dato
ci dà una indicazione piuttosto significativa sulla usabilità del sistema. Esso
andrebbe poi meglio interpretato con l’aiuto di informazioni più dettagliate
sugli utenti e su quali compiti hanno avuto i problemi maggiori.
Come condurre un test di usabilità
Come abbiamo già detto, è
preferibile che il team che conduce il test sia costituito da almeno due
persone. Una avrà il compito di dirigere le attività e di interloquire con gli
utenti, e nel frattempo verificare che le registrazioni, se vengono fatte,
procedano correttamente. L’altra osserverà con attenzione il comportamento
dell’utente durante il test, senza interferire, prendendo appunti sulle
situazioni più significative. Quest’attività è molto importante, anche nel caso
in cui il test venga registrato. Infatti, l’esame di una registrazione può
richiedere molto tempo (diverse ore per ogni ora di registrazione). Se
l’osservatore ha già localizzato durante il test i problemi principali,
nell’analisi della registrazione si potrà concentrare sui punti critici, con un
significativo risparmio di tempo.
Un test di usabilità viene condotto in quattro fasi
successive, come indicato in Figura
14.
Esaminiamole separatamente.
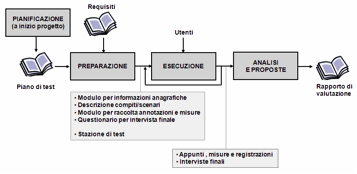
Figura 14. Le fasi di un test di usabilità
Pianificazione
L’organizzazione di un
test di usabilità dipende in modo sostanziale dagli scopi da raggiungere, che
dipendono dalla natura del prodotto e dalla strategia della sua realizzazione.
Come abbiamo visto nel Capitolo 9, i prototipi prodotti in un ciclo di sviluppo
iterativo possono essere di tipo diverso, e dovrebbero essere realizzati in
accordo a un piano di lavoro definito all’inizio del progetto. Il piano
dovrebbe specificare la natura e lo scopo di ogni prototipo: i test su di esso
dovrebbero essere progettati di conseguenza.
Anche lo standard ISO 13407 raccomanda che
l’intero processo di valutazione sia pianificato in anticipo, precisando, tra
l’altro, “quali parti del sistema devono essere valutate e come; quali
prototipi dovranno essere realizzati, come deve essere eseguita la valutazione
e con quali risorse; quali dovranno essere le interazioni con gli utenti e come
dovrà essere condotta l’analisi dei risultati.”
Preparazione del test
Nella fase di preparazione del
test, il team di valutazione deve innanzitutto definire il numero e il profilo
degli utenti campione e i compiti (o gli scenari, nel caso dei test di
scenario) che si richiederà loro di svolgere. Sono decisioni molto delicate,
poiché da esse dipenderà in larga misura l’utilità del test.
Nel caso di un test formativo
inserito nel processo di sviluppo, si seguirà spesso la regola di Nielsen di
cui abbiamo parlato più sopra. Il lavoro potrà anche essere svolto dagli stessi
progettisti, se lo sanno fare, senza il supporto di un esperto di usabilità. Nel
caso, invece, in cui il test di usabilità costituisca un evento a sé stante,
per esempio per valutare l’opportunità di interventi migliorativi su un sistema
esistente, occorrerà un’organizzazione più robusta. La durata di ogni singolo test
potrà essere più lunga (ma di solito non durerà più di un’ora o un’ora e mezza
al massimo per ciascun utente). Il numero degli utenti sarà maggiore, tenendo
comunque presente che normalmente si ritiene più produttivo fare tanti test con
pochi soggetti che pochi test con molti soggetti. In questi casi anche
l’organizzazione del team di valutazione dovrà essere potenziata. In un test di
una certa ampiezza si raccolgono informazioni in grande quantità, e bisogna poi
saperne trarre le dovute conclusioni. In questo caso, l’inserimento nel team di
un professionista dell’usabilità è fortemente consigliabile.
Proseguendo nella preparazione
del test, il team di valutazione deciderà quindi le misure da raccogliere, e
predisporrà tutti gli aspetti relativi alla logistica per l’esecuzione delle
prove (postazione di lavoro e di osservazione, strumenti di registrazione, e
così via), in modo che queste possano avvenire senza troppi disturbi. Preparerà
infine i materiali necessari allo svolgimento dei test, e in particolare:
· un modulo per raccogliere le
informazioni sugli utenti: informazioni anagrafiche, livello di esperienza,
competenze nell’ambito specifico del sistema;
· il testo con le istruzioni
per lo svolgimento delle prove da consegnare agli utenti: la descrizione di
compiti e scenari dovrebbe essere concisa, ma particolarmente chiara, per
evitare chiarimenti e spiegazioni durante lo svolgimento della prova;
· la modulistica che gli
osservatori utilizzeranno per raccogliere le misure relative all’esecuzione di
ciascun compito, e le loro annotazioni durante il test. Questi moduli devono
permettere di annotare rapidamente le informazioni utili, e quindi dovrebbero
essere predisposti in funzione delle caratteristiche del test. Per esempio, si
possono preparare stampe delle schermate video del sistema, su cui annotare gli
aspetti critici, e una tabella come quella di Figura
13 per raccogliere le misure relative ai singoli utenti
e compiti;
· un questionario per le interviste
finali degli utenti, di cui parleremo fra poco.
Esecuzione del test
La fase di esecuzione del test
vera e propria, se tutto è già bene organizzato e ci si limita a un test con pochi
utenti, non dura in genere più di qualche ora complessivamente. Un test più
ampio richiederà, al massimo, una o due giornate di lavoro.
È molto importante che, durante
il colloquio di spiegazione iniziale con ciascun utente, sia chiarito molto
bene che l’obiettivo della prova è valutare
il sistema, e non la capacità dell’utente di svolgere bene e rapidamente
i compiti assegnati. È indispensabile che il facilitatore metta ogni utente a
suo agio, per ridurre al massimo lo “stress da esame” che non sarà mai del
tutto eliminabile, e che potrebbe compromettere l’esito della prova. Bisogna
spiegare bene che se una persona trova difficile usare il sistema, questo non
avviene perché è incapace, ma perché il sistema è progettato male. A ogni
utente dovrà poi essere esplicitamente garantita la riservatezza delle
eventuali registrazioni che saranno effettuate, che dovranno essere visionabili
esclusivamente dai team di valutazione e di progetto, a meno che egli non firmi
un’esplicita liberatoria che autorizzi una diffusione più ampia.
I test devono essere condotti
singolarmente, un utente alla volta. È opportuno prevedere, per ciascuno, un breve
periodo di familiarizzazione con il sistema, prima del test vero e proprio. Durante
lo svolgimento della prova i valutatori dovranno interferire il meno possibile:
solo il facilitatore è autorizzato a parlare con l’utente, e i suoi interventi
dovranno essere limitati allo stretto indispensabile, per non influenzarne il
comportamento. Il suo scopo sarà esclusivamente quello di rassicurarlo in caso
di difficoltà, incitandolo a proseguire con tranquillità, senza mai suggerire
le azioni da compiere e senza fornire o chiedere spiegazioni. Dovrà invece,
quando necessario, ricordargli il “thinking aloud”, cioè di commentare ad alta
voce ciò che sta facendo: che cosa si propone di fare, che cosa vede sullo
schermo, come pensa di dover proseguire, quali difficoltà sta incontrando,
quali dubbi ha, e così via. Questo sarà molto utile agli osservatori che
prendono appunti, e che dovranno poi ricostruire, anche con l’aiuto delle
eventuali registrazioni, le cause dei problemi incontrati. Il facilitatore avrà
poi il compito di interrompere l’utente nel caso che, durante l’esecuzione di
un certo compito, abbia incontrato difficoltà che non riesce a superare.
Al termine del test
d’usabilità, è utile intervistare gli utenti sull’esperienza che hanno appena
fatto. In queste interviste, che conviene condurre utilizzando un questionario
appositamente predisposto, l’intervistatore chiederà, a ogni utente, quali
sono, a suo parere, i punti di forza e di debolezza del sistema, gli aspetti
che dovrebbero essere migliorati, e quelli che ha gradito maggiormente. Queste
interviste possono fornire ulteriori indicazioni, ma non devono sostituire le
prove d’uso del sistema. Infatti gli utenti si limitano spesso a indicazioni
generiche, e sono raramente in grado di individuare con precisione le cause
delle loro dfficoltà.
Analisi dei risultati e proposte migliorative
L’ultima fase del test è quella
in cui si analizza il materiale raccolto (appunti ed eventuali registrazioni audio/video)
e si traggono le conclusioni. È la fase più delicata, e richiede tempo e grande
cura. Anche una sessione di test breve, se riesaminata con attenzione, può
fornire molte informazioni. Ogni gesto, ogni frase, ogni esclamazione
dell’utente è un indizio importante, che va considerato e discusso dal team di
valutazione, per individuarne cause e implicazioni.
Ci sono alcuni errori tipici
dei valutatori poco esperti, che vanno evitati. Il primo è di limitarsi
sostanzialmente a riportare i giudizi espressi dagli utenti nelle interviste
successive al test. Questi sono utili, ma costituiscono solo una porzione abbastanza
marginale dei risultati di un test ben condotto. Infatti spesso l’utente tende
a esprimere giudizi o sensazioni di carattere generale (es.: “la fase di login è
troppo complicata e mi chiede informazioni inutili”), senza essere in grado di
risalire con precisione a tutte le cause di tali giudizi o sensazioni.
Se lo fa, la sua analisi potrebbe rivelarsi sbagliata: non possiamo pretendere
che l’utente sia un esperto di usabilità. Può capitare anche che l’utente, dopo
una sessione di prova che ha mostrato evidenti difficoltà, esprima un giudizio
sostanzialmente positivo sul sistema. Quindi il valutatore non deve mai
accontentarsi dei commenti degli utenti, ma deve sempre compiere un’analisi diretta
e dettagliata dei loro comportamenti, esaminando il materiale registrato o gli
appunti presi durante le sessioni di prova. Il secondo errore tipico è quello
di limitarsi all’elencazione di poche difficoltà macroscopiche, senza andare in
profondità. Occorre, invece, elencare analiticamente tutti i problemi
individuati, grandi e piccoli: solo così il test ci darà il massimo rendimento.
Il risultato di quest’analisi è
un elenco dei problemi incontrati nello svolgimento di ciascun compito,
descritti in modo circostanziato. A ciascun problema il team di valutazione
assegna un livello di gravità, in base a considerazioni di vario tipo: il
numero di volte che tale problema è stato evidenziato nei test, il livello
d’esperienza degli utenti che hanno sperimentato il problema, l’effetto che il
problema ha avuto sul completamento del compito (il problema ha impedito di
portarlo a termine, o l’utente ha trovato comunque una soluzione o un percorso
alternativo che gli ha permesso di arrivare al risultato desiderato?).
L’elenco dei problemi rilevati
sarà poi riesaminato per produrre un elenco di interventi proposti per
migliorare il prodotto (o il prototipo). Esse dovranno essere organizzate in
diversi livelli di loro priorità, per esempio:
· Priorità 1: intervento indispensabili e urgenti
Sono interventi per risolvere problemi bloccanti, senza i quali il sistema non può essere utilizzato per gli scopi per cui è stato progettato.
· Priorità 2: interventi necessari
Interventi che risolvono problemi di usabilità gravi, ma che non impediscono all’utente di utilizzare il sistema. Per esempio, possono esistere dei percorsi alternativi che permettono comunque all’utente di raggiungere i suoi obiettivi.
· Priorità 3: interventi auspicati
Interventi che risolvono problemi di usabilità di minore gravità. Per esempio, problemi che si verificano in situazioni particolari e poco frequenti, e che comunque sono superabili con difficoltà limitate.
Il rapporto di valutazione
L’esito
di una valutazione di usabilità dovrebbe essere descritto in modo accurato, non
solo per test di tipo sommativo, ma anche nel caso dei test effettuati durante il
processo iterativo di progettazione e sviluppo. Per questo, si utilizza un documento
chiamato rapporto di valutazione. Esso non solo descrive i risultati dei
test effettuati, ma fornisce anche evidenza del fatto che essi siano stati
condotti con metodi adeguati. In particolare, che gli utenti utilizzati nelle
prove siano rappresentativi delle categorie identificate nei requisiti e che
siano in numero adeguato, che i test effettuati siano sufficienti per fornire
indicazioni attendibili nei vari casi e contesti d’uso e, infine, che siano
stati usati metodi appropriati sia nella conduzione del test sia nella raccolta
dei dati.
Lo
standard ISO 13407 identifica tre tipi fondamentali di rapporti di valutazione,
a seconda che il loro scopo sia fornire feedback per la progettazione, o
provare la conformità a specifici standard oppure, infine, fornire evidenza del
raggiungimento di obiettivi human-centred, per esempio in termini di usabilità
o salute o sicurezza per l’utente.
Uno schema generale per la stesura del rapporto di
valutazione, un po’ più semplice di quello suggerito dall’ISO 13407, può essere il seguente.
Identificazione
del documento
Riportare i nomi degli autori, la data e la versione del
documento.
Sommario
Riportare
una sintesi dello scopo del documento e delle sue conclusioni.
Prodotto
valutato
Descrivere
brevemente il prodotto o il prototipo sottoposto a test, con ogni informazione che
lo identifichi con precisione. Indicare le aree funzionali sottoposte al test.
Obiettivi
della valutazione
Descrivere gli obiettivi
specifici perseguiti nella valutazione descritta nel documento.
Metodologia
utilizzata
Specificare quanti utenti hanno partecipato al
test, il loro livello di esperienza e le loro caratteristiche in relazione al
prodotto in esame. Specificare i compiti o gli scenari assegnati, il contesto
in cui si è svolto il test e la strumentazione utilizzata. Descrivere come è
stato condotto il test e da chi, quanto tempo è durato (per ciascun utente e
complessivamente), quali misure sono state raccolte, il ruolo degli osservatori
e come sono stati analizzati i risultati.
Sintesi
delle misure
Fornire una tabella di sintesi delle misure
raccolte. Per esempio, i tempi di esecuzione e la percentuale dei vari compiti
che sono stati portati a termine con successo, complessivamente e per ciascun
utente. Aggiungere commenti ove opportuno.
Analisi
dei risultati
Descrivere analiticamente i problemi incontrati
da ciascun utente durante il test, compito per compito, allegando ove opportuno
degli screen shot significativi e assegnando ad ogni problema un livello di
gravità. Ogni problema sarà numerato, per un più facile riferimento. Descrivere
in dettaglio, se significativi, reazioni e commenti degli utenti, registrati
durante le prove. Questa è la sezione principale del documento, e dovrà
contenere tutte le informazioni utili a formulare i possibili interventi per
rimuovere i problemi descritti, senza che sia necessario tornare a esaminare il
prodotto. Consisterà in genere di molte pagine.
Sintesi
delle interviste agli utenti
Sintetizzare i risultati delle interviste
effettuate a ciascun utente dopo l’esecuzione del test.
Raccomandazioni
Inserire la descrizione analitica degli
interventi migliorativi proposti, raggruppati per livelli di priorità (per esempio: priorità 1: interventi indispensabili e
urgenti; priorità 2: interventi necessari ma meno
urgenti; priorità 3: interventi auspicati). Per ogni intervento proposto si farà
riferimento al problema relativo, descritto nella sezione precedente. Gli
interventi saranno numerati, per una facile tracciabilità.
Allegati
Allegare i moduli anagrafici compilati dagli utenti,
la descrizione dei compiti/scenari data agli utenti prima del test, e tutti i
questionari compilati nelle interviste finali. Allegare anche il materiale
rilevante prodotto durante il test (per esempio, le riprese video).
Test di usabilità: costi e benefici
Qualunque
sia la tecnica utilizzata, i test con gli utenti sono indispensabili. Infatti,
le cause delle difficoltà incontrate dagli utenti possono essere moltissime.
Analizzare un sistema “a tavolino”, come nelle valutazioni euristiche, anche se
può permetterci d’individuare numerosi difetti, non è mai sufficiente. I
problemi possono essere nascosti e verificarsi soltanto con certi utenti, in relazione
alla loro esperienza o formazione. Cose ovvie per chi già conosce il sistema o
sistemi analoghi possono rivelarsi difficoltà insormontabili per utenti meno
esperti. Un test di usabilità ben condotto mette subito in evidenza queste
difficoltà. La necessità del coinvolgimento degli utenti è affermata con
chiarezza dalla stessa ISO 13407:
La valutazione condotta soltanto da esperti,
senza il coinvolgimento degli utenti, può essere veloce ed economica, e
permettere di identificare i problemi maggiori, ma non basta a garantire il
successo di un sistema interattivo. La valutazione basata sul coinvolgimento
degli utenti permette di ottenere utili indicazioni in ogni fase della
progettazione. Nelle fasi iniziali, gli utenti possono essere coinvolti nella
valutazione di scenari d’uso, semplici mock-up cartacei o prototipi parziali.
Quando le soluzioni di progetto sono più sviluppate, le valutazioni che
coinvolgono l’utente si basano su versioni del sistema progressivamente più
complete e concrete. Può anche essere utile una valutazione cooperativa, in cui
il valutatore discute con l’utente i problemi rilevati.
In
Italia i test di usabilità sono ancora poco praticati. I motivi principali sono due. Il primo
è senz’altro costituito dall’insufficiente diffusione di una cultura
dell’usabilità, sia presso gli utenti sia presso gli stessi progettisti La
sensibilità verso questi problemi è tuttora molto bassa, e gli esperti di
usabilità, nelle università e nelle aziende, sono pochi. Il secondo motivo è
che – si sostiene – i test di usabilità costano troppo. Si tratta
di una convinzione diffusa ma sbagliata: i test di usabilità si possono fare
rapidamente e con costi veramente molto contenuti. Un test di usabilità ben
strutturato, di tipo sommativo, può coinvolgere 10-15 utenti, o più. Ma, come
abbiamo visto, i test di tipo formativo possono essere fatti in modo molto più
snello, con ottimi risultati.
Esiste
anche un terzo motivo che a volte viene addotto per non fare test di usabilità.
Si
sostiene, in sostanza, che i test di usabilità non ci danno dei risultati
oggettivi, ma ci segnalano soltanto le risposte soggettive di determinati
individui di fronte al sistema. Questa è la tipica reazione di autodifesa dei
progettisti: la “colpa” dei problemi non è nel sistema, è di quel particolare
utente, che non è capace di usarlo come dovrebbe. Altri utenti, più in gamba,
non incontrerebbero difficoltà. Il ragionamento è insidioso, perché,
apparentemente, difendibile. Più o meno, è questo: test “scientifici”, con
risultati statisticamente validi, dovrebbero coinvolgere moltissimi utenti:
almeno molte diecine. Questo non si può fare, sarebbe troppo lungo e costoso. I
test con pochi utenti non sono significativi: le persone sono troppo diverse
l’una dall’altra. Perché dovremmo dar peso alle reazioni soggettive di pochi
individui e avviare costose modifiche soltanto sulla base di queste reazioni?
Il fondamento di queste
obiezioni è formalmente inappuntabile: un esperimento o è condotto con il
necessario rigore, o è inutile: non permette di trarre alcuna conclusione
valida. Ma dal punto di vista
pratico non regge: un test di usabilità – a meno che non sia condotto su
una popolazione vasta di utenti e con metodi statistici rigorosi, il che non
succede praticamente mai – non è un esperimento scientifico, fatto per
confermare determinate ipotesi. Il suo scopo è di verificare le reazioni di certi
soggetti a determinati stimoli. Queste reazioni sono un fatto oggettivo, si
possono vedere e registrare con la telecamera. Anche le reazioni di pochi
individui ci possono insegnare qualcosa, se
opportunamente decodificate e interpretate. Ed è soprattutto quest’analisi
e interpretazione ciò che interessa, e che dà valore al test. Essa ci fornisce
una comprensione migliore del nostro sistema, e di come può essere usato. Dai
test di usabilità possiamo scoprire aspetti che abbiamo trascurato nella
progettazione e che possiamo migliorare.
Peraltro, in un tipico test di
usabilità, molto spesso il conduttore non ha bisogno, per così dire, di
“leggere fra le righe”. In genere,
quando ci sono dei problemi, le reazioni degli utenti sono evidenti, a volte
addirittura scomposte, e di significato inequivocabile. Per capire perché è necessario fare test di usabilità dobbiamo vederne
qualcuno. Leggerne su un report scritto può non bastare a
convincerci. Ma altra cosa è vedere con i nostri occhi una persona in carne e
ossa, che ha accettato di sottoporsi al test, e che si mostra gentile,
disponibile, interessata e volonterosa e che, dopo diversi tentativi non riesce
a portare a termine un compito, e allora si fa rossa in viso, balbetta frasi
incoerenti, e poi abbandona sbattendo, con un gesto di stizza, il mouse contro
il tavolo… Queste reazioni, nella loro specificità certamente soggettive e
individuali, costituiscono comunque un dato oggettivo, che non possiamo
trascurare. Le difficoltà macroscopiche emergono subito, anche con pochi utenti,
e questo è il senso della “regola di Nielsen”. Diverso è il caso dei problemi
minori, in cui le differenze di esperienza fra i vari utenti possono contare
molto. In questi casi possono essere necessari molti test e molti soggetti e,
soprattutto, una buona esperienza e capacità di analisi da parte degli
osservatori.
In
conclusione, i test di usabilità sono parte necessaria e ineliminabile del
processo di progettazione e sviluppo di un sistema interattivo. L’usabilità non
è un optional che si possa eliminare per abbassare i costi, come gli
accessori in un’auto economica. Così come non si possono eliminare i test per
verificare il corretto funzionamento del software. Molto semplicemente, se il
prodotto è poco usabile, o non funziona, gli utenti non lo useranno.
Altre tecniche di valutazione
In
questo capitolo, coerentemente con la natura introduttiva di questo libro, ci
siamo limitati a descrivere le due tecniche principali di valutazione
dell’usabilità di un sistema interattivo: le valutazioni euristiche e i test di
usabilità con gli utenti. Sono due tecniche di carattere generale, che hanno lo
scopo di individuare i principali problemi di usabilità di un sistema. Le
abbiamo descritte con finalità essenzialmente pratiche, enfatizzando le
tecniche che ci permettono di raggiungere risultati utili in fretta e a costi
limitati (discount usability). Indagini su aspetti più specifici andranno
condotte con tecniche apposite, per esempio effettuando studi sul campo, oppure
indagini mirate attraverso interviste o focus group, oppure ancora esperimenti
di laboratorio con utenti scelti in modo statisticamente rappresentativo.
In
particolare, la conduzione di esperimenti di laboratorio condotti con
metodologie rigorose su campioni rappresentativi di utenti costituisce oggi uno
strumento importante per l’avanzamento delle conoscenze sull’usabilità e sui
principi della Human-Computer Interaction in generale. Possiamo affermare che
la HCI possiede due anime, molto diverse ma ugualmente importanti e complementari:
un’anima progettuale e un’anima sperimentale. La prima ci porta a concepire,
progettare e realizzare soluzioni e strumenti nuovi; la seconda ci permette di
verificarne, sperimentalmente, la validità. È quindi comprensibile che una parte rilevante degli
studiosi di questa disciplina si occupi della conduzione di esperimenti
condotti con tecniche scientifiche rigorose. Queste richiedono competenze
specifiche, anche di statistica, che esulano dagli scopi di questo libro, e per
le quali rimandiamo ai testi specializzati.
Ripasso ed esercizi
1. Descrivi
sinteticamente il metodo delle ispezioni per valutare l’usabilità di un
sistema, specificandone vantaggi e svantaggi.
2. Che
cosa s’intende per valutazione basata su euristiche? Quali sono i vantaggi e
gli svantaggi?
3. Descrivi
sinteticamente il metodo di ispezione dell’usabilità di un sistema basato sulle
euristiche di Nielsen.
4. Applicando
il metodo di valutazione basato sulle euristiche di Nielsen, come valuteresti
l’usabilità dei comandi (esterni e interni) dell'ascensore di casa tua, e
perché?
5. Qual
è la differenza fra i test di compito e di scenario? E fra test formativi e
sommativi?
6. Che
cosa è la tecnica del "thinking aloud"? Perché la si usa spesso?
7. Riassumi
e motiva la regola di Nielsen.
8. Devi
organizzare un test di usabilità di un nuovo modello di penna stilografica.
Come lo organizzi e lo conduci?
9. Quali
misure si raccolgono normalmente durante un test di usabilità? A che cosa
servono?
10. Che cosa
si intende per “discount usability”?
Approfondimenti e ricerche
1. Cerca su http://www.youtube.com
esempi di registrazioni di test di usabilità di vario tipo (prototipi di carta,
dispositivi mobili, applicazioni per personal computer). Puoi iniziare con i
video prodotti dagli studenti che hanno usato questo libro, cercando le
seguenti parole chiave: “test usabilità”, “usability test”, “polillo”.
2.
Per una interessante
discussione retrospettiva sulla discount usability, si veda la Alertbox del
settembre 2009 di Jakob Nielsen: Discount
Usability: 20 years del settembre 2009, sul suo sito http://www.useit.com/alertbox/discount-usability.html.
3.
Ricerca in rete un
software gratuito per gestire i test di usabilità, e sperimentalo. Per esempio,
puoi utilizzare Morae (http://www.techsmith.com),
uno dei prodotti più noti. Non è gratuito, ma permette prove gratuite per un
periodo limitato.