11.
Progettare per
l’errore
Sintesi del capitolo
Questo
capitolo discute la nozione di errore umano nel dialogo uomo-macchina e
presenta alcune linee guida per il trattamento degli errori compiuti
dall’utente, approfondendo quanto già detto nel Capitolo 10. Dopo una
classificazione dei principali errori in lapsus e sbagli, si descrivono le
principali tecniche di prevenzione a disposizione del progettista. Si discutono
poi le linee guida per una corretta diagnosi degli errori. Infine si descrivono
i processi di ripristino, suddividendoli in due tipologie: forward recovery e
backward recovery. Il capitolo contiene numerosi esempi.
L’errore umano
Nel Capitolo 10 abbiamo
elencato le raccomandazioni fornite dallo standard ISO 9241-110 per la
realizzazione di sistemi error-tolerant, cioè quei sistemi che consentono
all’utente di raggiungere facilmente gli obiettivi desiderati nonostante gli
errori compiuti nell’interazione. Questo capitolo tratta in modo più
dettagliato questo argomento che, nonostante la sua grande importanza pratica
ai fini dell’usabilità di un sistema, viene spesso trascurato dai progettisti.
Anche l’utente più esperto
commette degli errori. Questo è inevitabile, se si pensa che spesso, nei
compiti quotidiani, c’è un solo modo di fare le cose nel modo corretto, ma
molti modi di sbagliare. Pensiamo al compito di cuocere un uovo sodo: si tratta
di un processo elementare, ma la lista dei possibili errori è piuttosto lunga.
Possiamo romperlo per un movimento troppo brusco mentre lo prendiamo dal frigorifero,
se lo immergiamo nell’acqua bollente quando è troppo freddo il guscio tende a
incrinarsi, possiamo sbagliare il tempo di cottura o rovinarlo mentre lo
sgusciamo. Ci può cadere per terra mentre lo portiamo in tavola. Infine,
possiamo non accorgerci, prima di assaggiarlo, che si tratta di un uovo
rancido.
Il progettista deve
innanzitutto comprendere che l’utente che
sbaglia non è un utente sbagliato, ed evitare di colpevolizzarlo, o
pretendere da lui un’impossibile perfezione. Deve accettare il fatto che l’utente sbaglia perché il sistema gli
consente di sbagliare e questo, in ultima analisi, è un difetto ascrivibile
a cattiva progettazione. Il progettista deve allora predisporre tutti gli
accorgimenti per evitare, per quanto possibile, questa eventualità e gestirla
nel modo più corretto quando si verifica.
A questo scopo, deve
innanzitutto comprendere meglio la natura dell’errore umano. Che cosa significa
errore? Se cerchiamo nel dizionario la definizione di questo termine, troviamo,
per esempio:
Atto,
e effetto di allontanarsi dalla verità o dalla norma convenuta[1]
Questa definizione non è di
grande aiuto, perché troppo generale. Noi siamo interessati a comprendere
l’errore umano dal punto di vista psicologico e operativo, non filosofico. Un
errore compiuto dall’uomo – e in particolare dall’utente di un sistema
interattivo - può avere cause diverse e produrre effetti differenti: se
conosciamo le cause possibili, possiamo cercare di prevenirlo; se ne conosciamo
gli effetti, possiamo cercare di limitarli. Fortunatamente l’errore umano è
stato ampiamente analizzato dagli studiosi di scienze cognitive. James Reason,
nel suo libro Human Error ne dà la
seguente definizione operativa:
“Errore” sarà inteso come un termine
generico per comprendere tutti i casi in cui una sequenza pianificata di
attività fisiche o mentali fallisce il suo scopo, e quando questo fallimento
non possa essere attribuito all’intervento di qualche agente casuale[2].
Nello stesso libro, si trova
una classificazione molto utile per i nostri scopi, illustrata nella Figura
1. In questo schema, un'azione è considerata corretta
quando si verificano tre condizioni: 1) l’utente aveva l'intenzione di agire,
2) l'azione è proceduta come desiderato, 3) l'azione ha ottenuto il suo scopo.
Se non si verificano tutte queste tre condizioni, si hanno quattro fondamentali
tipi di errori.

Figura 1. Classificazione degli errori
· Azione intenzionale ma errata (mistake)
Per questo tipo di errore, in inglese si usa il termine mistake.[3] Esso si verifica quando l’utente ha agito con intenzione, l'azione si è svolta come aveva pianificato, ma non ha ottenuto lo scopo prefissato. In sostanza, l’utente ha compiuto un’azione credendo che portasse a un determinato risultato, ma così non è stato. Ad esempio, per accendere la luce in una stanza ha premuto l'interruttore sbagliato, credendo che fosse quello giusto. Aveva l'intenzione di agire (accendere la luce premendo un determinato interruttore), ha effettivamente premuto quell'interruttore, ma lo scopo non è stato raggiunto. Riprendendo il modello di Norman schematizzato nella Figura 2 del Capitolo 3, l’utente ha formulato l’intenzione corretta, ma ha specificato (ed eseguito) l’azione sbagliata.
· Azione non intenzionale (lapsus)
Per questo tipo di errore si usa più propriamente il termine latino lapsus o, in inglese, slip, che significano, letteralmente, “scivolata”. Si ha un lapsus quando, parlando o scrivendo, si sostituisce involontariamente una parola con un’altra (lapsus linguae o lapsus calami, nel caso della scrittura). Oppure, generalizzando, quando si compie involontariamente un’azione al posto di un’altra. Riprendendo l’esempio precedente, quando l’utente, volendo premere un determinato interruttore per accendere la luce, ha invece premuto involontariamente l’interruttore vicino. Tornando al modello di Norman, si ha quindi un lapsus quando l’utente, dopo avere formato l’intenzione corretta, e specificato un’azione corretta, ha invece eseguito l’azione sbagliata.
I lapsus sono molto frequenti, e possono verificarsi soprattutto quando l'azione corretta e l'azione sbagliata “si assomigliano”, per esempio quando due pulsanti sono fisicamente vicini. Oppure quando due compiti diversi hanno in comune una sequenza iniziale di azioni, e la sequenza finale in un caso viene eseguita di rado, e nell’altro molto spesso. Per esempio, se tutti i giorni si percorre in automobile la stessa strada per andare da casa all'ufficio, sarà facile, imboccando lo stesso percorso, "distrarsi" e arrivare davanti all'ufficio anche se la destinazione desiderata questa volta era diversa. Norman chiama questi tipi di lapsus “errori di cattura”, perché una sequenza (quella più familiare) “cattura” l’altra.
I lapsus possono essere evitati (o comunque resi poco probabili) progettando il sistema in modo che queste situazioni non si verifichino.
· Azione spontanea
In questo caso, l’azione è compiuta intenzionalmente, ma senza che l’utente avesse precedentemente l’intenzione di agire. Per esempio, quando qualcuno ci lancia improvvisamente un oggetto e, quasi per un riflesso automatico, lo afferriamo al volo, o ci proteggiamo con le mani. L’azione non era prevista, ma ci siamo trovati nella necessità di compierla. Un’azione spontanea non necessariamente deve essere classificata come errore: è tale solo quando produce effetti indesiderati.
· Azione involontaria
In questo caso, l’azione è del tutto non intenzionale. Per esempio, quando urtiamo involontariamente una persona oppure quando, mentre a tavola ci versiamo del vino, rovesciamo il bicchiere.
Per ciascuno di questi tipi di
errore, gli effetti possono essere molto diversi. Se tocco inavvertitamente una
persona sul tram, la cosa non ha grande importanza. Ma se tocco
inavvertitamente il pallone con le mani nei pressi della porta durante una
partita di calcio di serie A le conseguenze possono essere molto gravi. Come si
vedrà meglio nel corso di questo capitolo, spesso non esiste una dicotomia netta
fra errore e comportamento corretto.
Le
strategie che il progettista deve mettere in atto per limitare la possibilità e
le conseguenze dell’errore umano sono riassunte nella Figura 2. Innanzitutto, dovrà progettare il dialogo in modo
tale che l’errore risulti impossibile, o comunque poco probabile (prevenzione). Nel caso in cui l’utente dovesse comunque commettere un
errore, questo dovrebbe essere gestito. In particolare, individuato e spiegato
correttamente all’utente (diagnosi),
affinché egli possa correggere la situazione (recovery). Vediamo più in dettaglio le principali tecniche che
possono essere utilizzate a questi scopi.

Figura 2. Progettare per l’errore
Prevenzione
Anche
nei sistemi interattivi, prevenire è meglio che curare. Prevenire l’errore (error prevention) significa progettare il
sistema in modo che la possibilità di errori da parte dei suoi utenti sia
minima. In particolare, un’azione dell’utente non dovrebbe mai causare una
caduta del sistema o un suo stato indefinito. Alcune tecniche molto
diffuse per prevenire gli errori sono le seguenti:
· Diversificare le azioni dell’utente;
· Evitare comportamenti modali;
· Usare funzioni obbliganti;
· Imporre input vincolati;
· Non sovraccaricare la memoria a breve termine dell’utente;
· Richiedere conferme;
·
Usare
default inoffensivi.
Vediamole singolarmente.
Diversificare le azioni dell’utente
Questa tecnica serve a
prevenire i lapsus. Si tratta di fare in modo che le azioni che l’utente deve
eseguire per effettuare compiti diversi siano ben diversificate, in modo da
minimizzare la probabilità che l’utente ne esegua inavvertitamente una al posto
dell’altra. Per esempio, è bene
distanziare fisicamente i pulsanti o le voci di menu di uso più frequente da
pulsanti o voci di menu relative a comandi “pericolosi”. Si tratta di una
raccomandazione alquanto ovvia, che però non di rado è disattesa.
A volte questa indicazione è in
conflitto con quella, altrettanto corretta, di raggruppare fra loro i comandi
semanticamente correlati. La Figura
3 mostra
un esempio tipico di questa situazione di conflitto. Il programma Outlook della
Microsoft, come tutti i programmi di posta elettronica, associa a ogni
messaggio che si trova nella mailbox di input lo stato di Read o di Unread, a seconda che esso sia
stato letto o no dall’utente. I messaggi nello stato di Unread sono
evidenziati visivamente (normalmente in neretto), per permettere all’utente di
individuare le mail ancora da aprire. Nel menu Edit ci sono anche due comandi (Mark as Read e Mark as Unread) che permettono di modificare questi
stati. Ciò è molto utile quando l’utente, dopo aver letto un certo messaggio,
decide di non rispondere subito: per ricordarsi che la mail non è stata evasa,
potrà usare il comando Mark
as Unread, che la visualizzerà di nuovo in neretto. Il sistema fornisce
anche un comando Mark
All as Read, che pone tutti i
messaggi presenti nella mailbox di input nello stato di Read. Il comando è collocato immediatamente sotto gli altri due, e
può accadere di selezionarlo inavvertitamente al posto del contiguo Mark as Unread, con
esiti molto fastidiosi. Infatti, il sistema non consente di annullarne gli
effetti, e l’utente non avrà più modo di riconoscere i messaggi ancora da
leggere da tutti gli altri. Questo capita di frequente a chi, come chi scrive,
abbia l’abitudine di dare una prima scorsa alla posta per poi evaderla in un
secondo tempo. Il problema potrebbe essere evitato, allontanando il comando
pericoloso dagli altri due, oppure lasciandolo dove si trova ma chiedendo
conferma all’utente prima di eseguirlo. Quest’ultima soluzione, nel caso
specifico, è probabilmente la più corretta, perché lascia vicini tre comandi
funzionalmente correlati.
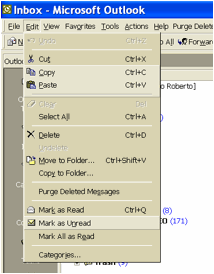
Figura 3. Un menu “pericoloso” (in Microsoft Outlook)
Evitare comportamenti modali
Chiamiamo modale un sistema che, a fronte di una stessa azione dell’utente,
si comporta diversamente a seconda dello stato in cui si trova e questo stato non è facilmente
riconoscibile dall’utente. Questo comportamento andrebbe sempre evitato: se
l’utente non è in grado di identificare facilmente lo stato del sistema, sarà
costretto a fare delle supposizioni, con un’elevata probabilità di commettere
errori.
Un esempio classico è quello
della funzione per il riconoscimento di una password in cui le minuscole sono
considerate diverse dalle corrispondenti maiuscole. Una password contenente caratteri minuscoli, se digitata
quando il sistema è nello stato di Caps Lock, viene
rifiutata. In molti sistemi, però, lo stato di Caps Lock non è visibile: l’utente, di
fronte a un rifiuto della password sarà perciò portato a credere di avere
sbagliato a digitare, e proverà di nuovo, anche più volte. Raramente attribuirà
il problema al tasto di Caps
Lock, che è
usato raramente (ma è “pericolosamente” vicino al tasto alzamaiuscole, che si
utilizza invece molto spesso). Il problema può essere facilmente evitato
rendendo ben visibile lo stato di Caps Lock, per esempio con un messaggio posto vicino
al campo d’immissione, dove l’utente rivolge la sua attenzione, come nelle
recenti versioni di Windows.
Un altro esempio spesso citato
è vi, un text editor in passato molto diffuso in ambiente Unix. Esso poteva trovarsi negli stati di attesa
carattere oppure di attesa comando. Digitando il carattere a, nel primo caso lo si
aggiungeva al testo in corso di stesura, nel secondo caso il sistema entrava
nello stato di append, e si
metteva in attesa di un carattere successivo. Se l'utente dimenticava lo stato
corrente, non era in grado di prevedere il comportamento del sistema. In
effetti, lo stato era segnalato sul video, ma ai bordi, in modo scarsamente
visibile perché lontano dal focus dell’attenzione dell’utente che, ovviamente,
era concentrata sulla posizione del cursore nel testo o su quella delle dita
sulla tastiera.
Il programma MacPaint della
Apple, uno dei primi programmi di disegno, risolveva un problema analogo in
modo elegante (Figura
4). L’utente
poteva selezionare da una paletta lo strumento desiderato, e il sistema
cambiava stato, per compiere le funzioni associate allo strumento. Il programma
evidenziava lo strumento selezionato, e quindi lo stato del sistema, sulla
paletta. Inoltre, con una tecnica adottata poi da molti programmi di questo
tipo, il cursore assumeva la forma dello strumento prescelto (nel nostro
esempio, la “matita”, per tracciare linee a mano libera). In questo modo, lo
stato del sistema era ben visibile proprio dove l’utente rivolge la sua
attenzione, e cioè sul cursore. Questa tecnica non è usata in PowerPoint (Figura
5), dove
il cursore mantiene sempre la forma di una croce, qualunque sia lo strumento
selezionato. Poiché gli strumenti vengono selezionati da un menu a tendina, che
subito si richiude, l’utente non ha modo di vedere lo stato del sistema, e
quindi di sapere quale figura verrà tracciata muovendo il cursore.
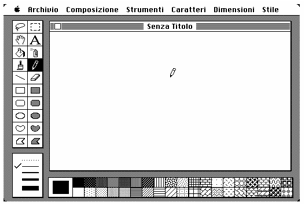
Figura 4. Cursore non modale (MacPaint, 1984)
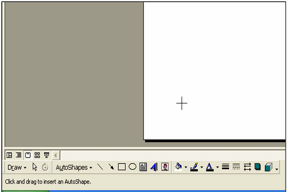
Figura 5. Cursore modale (da Microsoft PowerPoint 2003)
Usare funzioni obbliganti
Donald Norman definisce obbligante (in inglese: forcing function) una funzione in cui le
azioni dell’utente sono vincolate in modo tale che la mancata esecuzione di un
passaggio impedisca il successivo[4].
In tal modo, egli è obbligato a compiere le azioni nella sequenza corretta. Si
tratta di una tecnica molto efficace di prevenzione degli errori.
Nella vita quotidiana incontriamo
spesso delle funzioni obbliganti. A volte ci danno fastidio, perché limitano i
nostri comportamenti, ma ci risparmiano problemi più gravi. Per esempio, alcune
automobili emettono un segnale d’allarme quando apriamo la portiera con la
chiave inserita nel cruscotto. Questo per evitare che si esca dall’auto
dimenticando la chiave in macchina. Negli Stati Uniti, per un certo periodo le
automobili montavano un dispositivo che impediva la partenza quando le cinture
di sicurezza non erano allacciate. Il dispositivo risultò molto impopolare e fu
in seguito eliminato, ma era sicuramente molto efficace per prevenire un
comportamento errato del conducente.
A volte non ci rendiamo conto
di utilizzare funzioni obbliganti. Per esempio, quando mettiamo in moto l’automobile
con la chiave, in realtà compiamo con un solo gesto complesso tre operazioni:
1)- liberiamo il bloccasterzo, 2)- attiviamo il motorino di avviamento, 3)-
mettiamo in moto. Se queste azioni
fossero eseguibili separatamente (come si doveva fare un tempo), potremmo
eseguirle nell’ordine sbagliato, con problemi evidenti.
Anche nei sistemi software le
funzioni obbliganti sono importanti. Per esempio, a partire dal sistema Star
della Xerox, il primo computer
personale basato sulla metafora della scrivania, tutti i sistemi di questo tipo
adottano il modello oggetto-azione,
piuttosto che quello azione-oggetto. In
altre parole, l’utente seleziona prima l’oggetto su cui desidera operare (per
esempio, cliccando sull’icona di un file), e poi la funzione che vuole compiere
(per esempio, il comando Stampa per stampare il file
selezionato). Questa scelta, apparentemente arbitraria, permette di realizzare
funzioni obbliganti. Infatti, selezionando prima l'oggetto su cui operare, il
sistema è in grado di disabilitare tutte quelle voci di menu che corrispondono
ad azioni che non hanno senso su tale oggetto. Se saltiamo il primo passaggio
(la selezione dell’oggetto), il secondo non può essere eseguito, perché la voce
corrispondente del menu è disabilitata. Questo non sarebbe stato possibile
selezionando prima il comando e poi il suo argomento. Così, in Figura
6, che
rappresenta il primo Macintosh della Apple, tutte le voci che operano su file (Apri, Stampa, ecc.) sono
disabilitate, perché nessun file è stato selezionato.

Figura 6. Finder (Apple Macintosh, 1984)
Imporre input vincolati
Questa
tecnica, che generalizza quella delle funzioni obbliganti, consiste nel
permettere all’utente di fornire solo valori di input corretti.
In Figura
7 vediamo diversi modi di chiedere l’immissione di una
data. In (a), il sistema non pone alcun vincolo al formato della data. In (b),
(c) e (d) il sistema pone vincoli via via più stringenti. Quale soluzione è in
grado di prevenire meglio gli errori di digitazione? Possiamo facilmente
scartare la (a), perché troppo libera, e la (b), perché la (c), più
informativa, è sicuramente migliore. La (c) lascia ancora molta libertà
all’utente, che può digitare date formalmente scorrette. Nella (d), invece, i
valori selezionabili dai tre menu a tendina sono preimpostati, e quindi sempre
corretti. Non è però ovvio quale delle due ultime soluzioni sia la
migliore. Per deciderlo, non basta
un’analisi “a tavolino”: dovremmo fare delle prove d’uso con un sufficiente
numero di utenti. Infatti, la (d), che a prima vista ci sembrerebbe la più
sicura, evita sicuramente che l’utente digiti una data illecita, ma introduce
un altro problema, che nell’altra soluzione non si pone. In un menu a tendina
molto lungo il mouse può “scivolare” facilmente su una voce vicina a quella
desiderata, soprattutto quando si deve selezionare una delle voci più in basso.
Nel nostro esempio, le voci dei mesi sono soltanto 12, ma quelle dei giorni 31,
un numero abbastanza elevato. Quante sono quelle degli anni? Si inizia dal
1900? E qual è l’anno impostato come default nel campo? Se fosse l’anno meno recente, la
probabilità di dover selezionare una voce molto lontana sarebbe alta, e la
probabilità di errore più elevata.
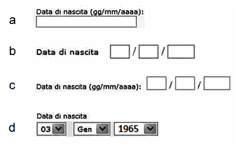
Figura 7. Esempi di input più o meno vincolati
Non sovraccaricare la memoria a breve termine
Nel Capitolo
4 sono state brevemente descritte le caratteristiche della memoria a breve
termine dell’uomo, in particolare la sua capacità limitata e la breve persistenza
dell’informazione. Dialoghi che sovraccaricano la memoria a breve termine
risultano faticosi per l’utente, e aumentano la probabilità che egli commetta
degli errori. Tipico è il caso dei messaggi pre-registrati dei call-center. A
chi telefona viene letto un elenco di servizi disponibili, che spesso è troppo
lungo per essere facilmente ricordato. Quando, durante l’enumerazione delle
alternative disponibili, l’utente ne identifica una che potrebbe
ragionevolmente fare al caso suo, la deve memorizzare e proseguire
nell’ascolto, nell’eventualità che ne vengano annunciate altre ancora più
pertinenti. Arrivato alla fine dell’enumerazione, non è raro il caso che,
avendo dimenticato le alternative presentate all’inizio, l’utente debba rifare
la telefonata e ascoltare da capo l’elenco.
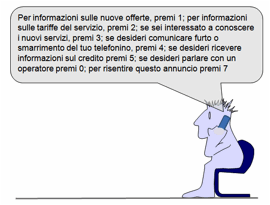
Figura 8. Sovraccarico della memoria a breve termine
Richiedere conferme
Il
sistema dovrebbe sempre avvertire l'utente quando questi richiede l’esecuzione
di azioni irreversibili o comunque potenzialmente pericolose, e domandare
conferma.
Le
richieste di conferma devono essere formulate in modo semplice e non ambiguo.
Un esempio corretto è mostrato in Figura 9,
in cui il messaggio è chiaro e le tre alternative ben distinte. Questo non è il caso del messaggio di Figura 9b,
causata dalla richiesta di uscire da un computer game senza avere prima salvato lo stato del gioco. Sarebbe
preferibile una forma più esplicita, che spiegasse meglio gli effetti delle tre
alternative, senza usare negazioni. Per esempio: Warning:
the game was not saved e, sui tre pulsanti: Exit without saving – Save
and exit
– Cancel.
Il
sistema non deve costringere l’utente a conferme troppo complicate, come quella
di Figura 9c:
qui non ci si accontenta di richiedere all’utente un semplice clic su un
pulsante di OK, ma lo si obbliga a digitare le tre lettere che compongono la
parola YES. Evidentemente, il progettista ha pensato che, così facendo, si
elimina la possibilità che l’utente
confermi per errore, ma la soluzione può essere considerata alquanto
vessatoria.
Le
richieste di conferma dovrebbero essere limitate ai soli casi di operazioni per
le quali l’eventuale annullamento fosse impossibile, o richiedesse molto
tempo. È infatti inutile
intralciare il lavoro dell’utente richiedendogli di confermare operazioni che,
se effettuate per errore, potrebbero essere facilmente annullabili.
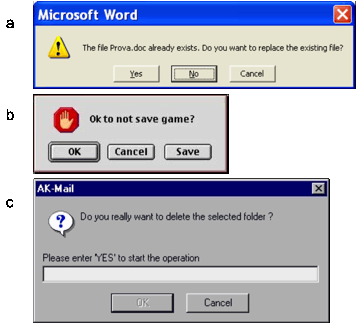
Figura 9.
Alcune richieste di conferma, da sistemi
degli anni ‘90:
a) da Microsoft Word, b) da un computer game per Apple Macintosh, c) da AK-Mail
per PC
Usare default inoffensivi
Questa tecnica consiste
nell'usare, per quanto possibile, valori di default inoffensivi. Il sistema, in
altre parole, non dovrebbe mai intraprendere per default l’azione più pericolosa
tra quelle possibili in un determinato contesto. Per esempio, la richiesta di
stampa di un documento di Microsoft Word 2007 ha come default l’opzione Pagine da stampare = Tutte. Non
viene richiesta alcuna conferma, nemmeno nel caso di documenti molto lunghi. A
chi scrive è capitato varie volte, durante la stesura di questo libro, di
avviare per errore la stampa di tutto il documento (un file di oltre 200
pagine!), invece che della sola pagina corrente, come desiderato. Un lapsus
costoso, le cui conseguenze avrebbero potuto essere evitate da una semplice
richiesta di conferma.
Diagnosi
Anche se il progettista adotta le tecniche di
prevenzione più appropriate, resterà sempre la possibilità che l’utente
commetta un errore. Pertanto, il sistema deve sempre controllare l’input e, nel
caso che si riveli scorretto, dovrà fornire all’utente una spiegazione
adeguata, che gli permetta di
recuperare la situazione in modo rapido, senza incertezze e senza stress.
Sono tre le funzioni che un messaggio di
errore ben progettato deve svolgere:
· Allertare, cioè segnalare che qualcosa non va;
· Identificare, cioè indicare che cosa non va, e perché;
· Dirigere, cioè spiegare all'utente i passi che deve compiere per ripristinare una situazione corretta: "ora devi fare questo".
In Figura 10 vediamo alcuni esempi di messaggi di errore. In (a), sono
presenti, anche se in forma molto sintetica, le tre funzioni sopra
indicate. L’utente viene allertato
per mezzo di un’icona ben visibile (un grosso punto di domanda su fondo bianco),
l’errore viene correttamente identificato con un testo breve ma chiaro (The selected printer is not available), e
viene indicata la possibilità di selezionare un’altra stampante: Do you want to select a different
printer?
Non si dice ancora come fare, si chiede soltanto di specificare le intenzioni:
presumibilmente, in caso di risposta affermativa, seguiranno ulteriori
indicazioni. Nel complesso il messaggio è accettabile, anche se, a ben vedere,
descrive “che cosa” non va, ma non spiega il perché. Infatti, l’indisponibilità
della stampante potrebbe avere cause diverse, tipicamente: 1)- l’utente ha dato
il comando di stampa senza modificare la stampante di default, che non
corrisponde a quella collegata al sistema, oppure 2)- la stampante selezionata
è quella corretta, ma è spenta. Anche se il software non fosse in grado di
discriminare fra queste due situazioni, potrebbe almeno indicare nel messaggio
il nome della stampante selezionata: The selected printer: <name> is not available. In
questo caso l’utente potrebbe comprendere immediatamente la causa del problema
e porvi rimedio.
Il messaggio di Figura
10b
corrisponde a una situazione di errore simile alla precedente (la stampante richiesta
non è disponibile). La scelta del colore dell’icona di allerta (giallo) vuole
correttamente segnalare che la situazione è probabilmente recuperabile. Il
messaggio d’identificazione dell’errore (Printer not found) è sintetico ma chiaro. Le
opzioni proposte all’utente sono però
incomprensibili. L’opzione Retry
non
ha senso se lo stato del sistema non cambia – per esempio accendendo la
stampante nel caso fosse spenta. Ma all’utente non viene data alcuna
indicazione in tal senso: se egli non fa nulla per correggere la situazione, la
riesecuzione del comando di stampa non può che portare allo stesso risultato.
Osserviamo le altre due opzioni: qual è la differenza fra Ignore e Abort? La prima, probabilmente, corrisponde a una presa d’atto del
messaggio e, implicitamente, alla richiesta di tornare allo stato precedente
alla richiesta di stampa. Ma allora sarebbe stato meglio usare il termine OK, oppure Cancel, a seconda delle convenzioni utilizzate
negli altri messaggi dello specifico sistema. Se questa interpretazione del
messaggio è corretta, allora Abort è inutile, e non corrisponde ad alcun’altra situazione
possibile. L’intestazione del messaggio (System error) è poi incomprensibile. Chi ha richiesto
una stampante che non c’è: l’utente o il sistema?
L’ultimo esempio (Figura
10c) usa
correttamente un’icona di colore rosso, per segnalare che è stato rilevato un
errore grave. Il simbolo usato dall’icona (una croce a x, come quelle usate per
segnalare i passaggi a livello) ci sembra più corretto del punto esclamativo
del messaggio precedente, che possiede una certa connotazione di rimprovero. Ma
la descrizione dell’errore – che identifica analiticamente la causa del
problema - è espressa in linguaggio tecnico, comprensibile solo ai
programmatori che hanno sviluppato l’applicazione.
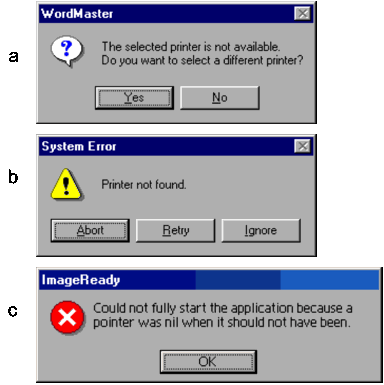
Come
abbiamo già osservato alla fine del Capitolo 10, è molto importante che il
messaggio non contenga alcun rimprovero (anche se sottinteso) all’utente. Al
contrario, molte applicazioni web dell’ultima generazione adottano la politica
opposta: il sito sembra chiedere scusa all’utente per averlo portato a
commettere un errore (self-deprecating
error messages), come nell’esempio di Figura
11, o della Figura 20 del Capitolo 10 (in basso a
destra).

Tutti
gli esempi discussi si riferiscono a singoli
errori. Sono frequenti, tuttavia, situazioni più complesse, in cui l’utente
compie più di uno sbaglio. L’esempio più tipico è la compilazione di una form
in un’applicazione web. L’utente immette i valori in diversi campi, e quindi ne
chiede l’invio al sistema, che li dovrà controllare segnalando gli eventuali
errori. Poiché più di un valore
può essere errato, ne possono seguire messaggi di errore multipli, che
devono possedere un’adeguata “granularità” ed essere facilmente associabili ai
valori cui si riferiscono.
La Figura
12, tratta
da un sito di commercio elettronico di molti anni fa, mostra un esempio
prodotto artificialmente, introducendo a bella posta un errore in ogni campo
della form. In questo caso, all’utente risulta molto difficile associare il
messaggio di errore al campo cui si riferisce. Infatti, il messaggio copre
interamente la form in cui sono stati commessi gli errori. I messaggi sono
troppo numerosi per essere facilmente ricordati (si ricordino le limitazioni
della memoria a breve termine). In pratica, l’utente è costretto a prendere appunti sulle correzioni da
effettuare, prima di tornare alla form
di imputazione dati.

Figura 12. Messaggi di errore multipli (da un sito di e-commerce, anni ’90)
La situazione di Figura
13 è più corretta, anche se perfettibile. In questo
caso, l’elenco dei numerosi errori rilevati è presentato mediante un piccolo
pannello sovrapposto alla form d’immissione dati, e facilmente spostabile sullo
schermo per rendere visibili tutti i campi.
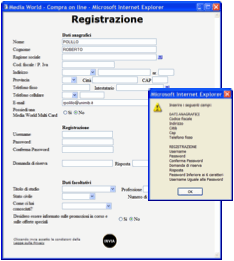
Figura 13. Messaggi di errore multipli (www.mediaworld.it, fine anni ’90)
La soluzione di gran lunga più
corretta è tuttavia quella esemplificata in Figura
14. In questo caso la segnalazione di errore è
visualizzata immediatamente sopra il campo errato (per maggiore evidenza, il
messaggio è in colore rosso vivo).
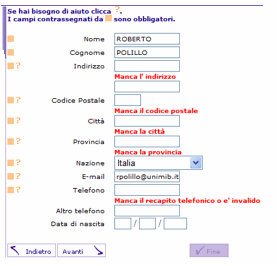
Figura 14. Tecnica corretta per la segnalazione di errori su una pagina web
La
spiegazione dell’errore e di come fare per correggerlo dovrebbe essere
particolarmente dettagliata e chiara quando il sistema si rivolga a utenti poco
esperti. Particolarmente interessante, a questo proposito, lo stile adottato da
Amazon nei suoi primi anni di esistenza, quando i siti di commercio elettronico
erano ancora poco noti alla maggior parte degli utenti del Web. Le spiegazioni
erano piuttosto estese, e spesso contenevano anche le motivazioni delle
richieste fatte all’utente, come nell’esempio di Figura 15.

Figura 15. Da http://www.amazon.com (circa 1995)
Per evitare una verbosità eccessiva,
può convenire esprimere il messaggio in forma sintetica, permettendo però
all’utente di richiedere spiegazioni più dettagliate.
Correzione
Quando l’utente commette un errore, deve essere possibile correggerlo. Questo processo può essere attuato, secondo i casi, dall’utente o dal sistema, o da entrambi, in modo cooperativo. Le situazioni possibili sono schematizzate nella Figura 16.[5] A partire da uno stato iniziale del sistema, l’utente compie un’azione, per esempio l’immissione del valore di una data in un campo di una form. Se l’azione è corretta, il sistema si porta nello stato desiderato, indicato in figura come stato finale. Per esempio, la data viene accettata e registrata in un file. Se invece l’azione non è corretta (per esempio, perché la data contiene degli errori formali), il sistema si porta in uno stato di errore. A partire da questo stato, il processo di correzione può avvenire con due strategie diverse, a seconda delle situazioni. Vediamole in dettaglio.
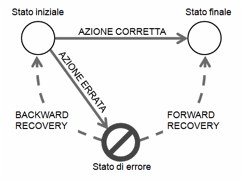
Figura 16. Ripristino dall’errore
Backward recovery
Secondo questa strategia, si tratterà di annullare le conseguenze negative dell’errore commesso, e riportare il sistema nello stato iniziale, dal quale l’utente potrà compiere, questa volta in modo corretto, l’azione che aveva sbagliato. Il processo per riportare il sistema nello stato iniziale si chiama ripristino - in inglese, backward recovery.[6] Nel caso elementare della data sbagliata, la backward recovery consisterà semplicemente nel cancellare dal campo di input il valore scorretto. Questo compito può essere svolto dall’utente oppure effettuato dal sistema, che sbianca il campo e posiziona il cursore all’inizio dello stesso, in attesa del nuovo input che – si spera – porterà allo stato finale desiderato.
In altri casi gli interventi di backward recovery possono essere più complessi. Per esempio, supponiamo che l’utente digiti una data formalmente corretta, ma diversa da quella che voleva immettere nel sistema e che si accorga del lapsus solo dopo avere confermato i dati. In questo caso, il sistema avrà accettato il valore, e lo avrà registrato nella base dati. La backward recovery richiederà quindi di modificare la base di dati: un’azione molto diversa da quella di prima.
La backward recovery può essere considerata un modo di “tornare indietro nel tempo”. Il modo più semplice di farlo è quello di utilizzare una funzione di undo, che annulli le conseguenze dell’ultima azione. I sistemi più evoluti forniscono la possibilità di annullare le ultime n azioni dell’utente, con n anche molto grande (undo a più livelli).
La
realizzazione di funzionalità di undo
non è sempre possibile, o praticabile. Infatti, possono essere necessarie
grandi quantità di memoria (per conservare gli stati precedenti), e gli
algoritmi di ripristino possono essere molto complessi. Tuttavia, in alcune
tipologie di sistemi, meccanismi di undo
sofisticati sono indispensabili, come per esempio nei programmi di grafica. La Figura
17 mostra
le funzioni di undo in PowerPoint 2007 (a) e Photoshop CS3 (b). In entrambi,
un pannello mostra l’elenco delle ultime azioni effettuate dall’utente. In
PowerPoint le azioni più recenti sono in alto, mentre in Photoshop sono in
basso. In entrambi i casi è possibile annullare le ultime n azioni con un solo
comando. In (a), sono state selezionate le ultime 4 azioni, che verranno
annullate al rilascio del mouse. In (b), selezionando un’azione, vengono
annullate tutte le azioni successive. In entrambi i sistemi l’undo può, a sua
volta, essere annullato (funzione di redo).
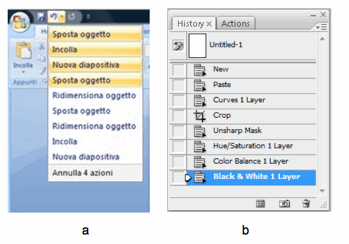
Figura 17. Undo a più livelli: PowerPoint 2007 (a) e Photoshop CS3 (b)
Forward recovery
Esistono situazioni in cui la correzione dell’errore avviene con un processo diverso. Invece di tornare allo stato iniziale e da lì ripetere l’azione, si cerca di raggiungere lo stato finale direttamente dallo stato di errore, senza prima tornare indietro. Questo processo si chiama forward recovery (Figura 16), e può essere effettuato automaticamente dal sistema, o richiedere l’intervento dell’utente. Un sistema che attua sistematicamente strategie di forward recovery si dice error tolerant.
La Figura
18 mostra il comportamento del motore di ricerca di
Google quando l’utente compie un errore di battitura. In questo caso l’utente
ha digitato nel campo di ricerca la parola chiave usibilità, invece di usabilità.
Poiché la parola digitata non esiste, il sistema la corregge e la interpreta
come usabilità: senza nulla chiedere
preventivamente all’utente, porta a termine la ricerca con questa parola.
L’utente è avvertito a posteriori: “Forse cercavi usabilità”.
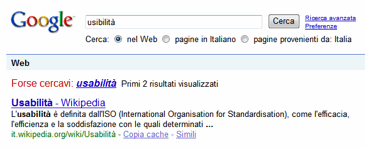
Figura
18.
Forward
recovery in http://www.google.com
La forward recovery può essere attuata anche dall’utente. Supponiamo di dover disegnare un quadrato, con PowerPoint o altro programma di grafica. Normalmente, occorre selezionare lo strumento “rettangolo” e, tenendo premuto il tasto Shift, tracciare la figura sul foglio visualizzato. Se l’utente si dimentica di tenere premuto il tasto Shift, la figura risultante sarà rettangolare. Per ottenere il quadrato potrà allora scegliere fra due strategie alternative: 1)- cancellare il rettangolo e ricominciare il disegno (backard recovery) oppure 2)- conservare il rettangolo e modificandolo fino a trasformarlo in un quadrato (forward recovery).
Ci sono casi in cui la backward recovery non è possibile, e l’unica strategia disponibile è la forward recovery. Se per esempio rompiamo un piatto, non saremo evidentemente in grado di ripristinarlo nella configurazione iniziale: potremo soltanto tentare di aggiustarlo incollando i vari pezzi.
I due ultimi esempi mostrano che, in molti casi, la recovery è imperfetta: si può solo arrivare a un’approssimazione dello stato desiderato. Un piatto aggiustato con la colla non è sicuramente uguale a un piatto integro, e un quadrato disegnato “a mano libera” potrebbe essere impreciso. In entrambi i casi, non si raggiungerà lo stato finale inizialmente desiderato, ma uno stato finale approssimato (Figura 19).

Figura 19. Ripristino imperfetto
In ogni caso, che si tratti di recovery all’indietro o in avanti, sarà bene che il progettista ricordi le raccomandazioni seguenti, che abbiamo già menzionato nel Capitolo 10 dedicato all’ISO 9241-110:
· Minimo
sforzo di correzione: i passi richiesti all’utente per correggere l’errore
dovrebbero essere il più possibile semplici, e il sistema dovrebbe porre in
atto ogni accorgimento per ridurne il numero e la complessità, svolgendo
automaticamente quelle operazioni che, per loro natura, non richiedono
l’intervento umano.
· Correzione differibile: l’utente dovrebbe poter rimandare la correzione dell’errore a un momento successivo. Questo, in virtù del principio di controllabilità, di cui abbiamo ampiamente trattato nel Capitolo 10. Può darsi, per esempio, che l’utente non possegga tutte le informazioni per correggere immediatamente i dati di input che il sistema non ha accettato.
· Correzione automatica modificabile: quando il sistema è in grado di correggere automaticamente l’errore commesso dall’utente, dovrebbe avvisarlo della correzione e permettergli di modificarla. Così, per esempio, se un correttore ortografico modifica la parola digitata dall’utente, l’utente dovrebbe esserne avvertito e poterne modificare la correzione.
Conclusioni
Il
senso di questo capitolo è che, nel dialogo con un sistema interattivo, non
esiste una dicotomia netta fra comportamento errato e comportamento corretto.
Parafrasando ancora una volta Donald Norman, tutta l'interazione uomo-macchina dovrebbe
essere trattata come una procedura cooperativa fra utente e sistema, dove gli
equivoci possono nascere da entrambe le parti, e devono essere risolti con
chiarezza e serenità. L’errore è parte integrante del comportamento umano, e
come tale deve essere previsto e accettato.
Un
sistema ben progettato non deve pretendere da chi lo usa una conformità
perfetta a regole precise e non modificabili, dovrà invece indicargli, nei modi
e nei contesti più opportuni in funzione delle diverse circostanze, che cosa
può o deve fare per raggiungere i suoi scopi, adattandosi in modo flessibile e
“intelligente” alle eventuali deviazioni che, in ogni caso, saranno numerose e
frequenti. Questo è il senso del principio di tolleranza verso l’errore che lo
standard ISO 9241-110 richiede ai sistemi usabili. Rispetto alla prassi
corrente nell’ingegneria del software, e nonostante i grandi progressi che
negli ultimi anni sono stati compiuti nell’usabilità dei sistemi, tutto ciò
richiede ancora un profondo cambiamento di mentalità. La prevenzione e il trattamento degli errori è una
componente ineliminabile e importante del lavoro di progettazione di un sistema,
e il progettista non la deve considerare un optional,
dedicato ad alcuni utenti particolarmente inaccurati o distratti.
Ripasso ed esercizi
1. Descrivi
la classificazione dell'errore umano secondo Reason, indicando un esempio per
ciascuna tipologia di errore.
2. Spiega la differenza fra lapsus e mistake, e indica due esempi di ciascuna tipologia di errore, tratti dalla tua esperienza personale dell'uso di qualche sistema interattivo.
3.
Che cosa significa "progettare per
l'errore"?
4.
Spiega che cosa si intende per comportamento
modale di un'interfaccia utente, e perchè tale comportamento va evitato. Indica
un esempio d’interfaccia modale, e spiega come questa interfaccia possa essere
resa più usabile.
5.
Che cosa s’intende per funzione obbligante?
Descrivine due esempi diversi da quelli indicati nel testo.
6.
Perchè, per prevenire errori, è necessario non
sovraccaricare la memoria a breve termine dell’utente?
7.
Quando è opportuno chiedere conferma all'utente
prima di eseguire una funzione da lui richiesta, e quando non lo è?
8.
Quali sono le caratteristiche di un buon
messaggio di errore?
9.
Quali sono le caratteristiche di un buon
messaggio di errore per transazioni sul Web?
10.
Spiega la differenza fra forward error recovery
e backward error recovery, con esempi.
11. Valuta la gestione degli errori nel tuo telefonino, e formulane un motivato giudizio dal punto di vista dell’usabilità.
Approfondimenti e ricerche
1. Il Web è ricco di esempi di messaggi d'errore mal progettati. Costruisci una galleria di esempi di messaggi “sbagliati”, raccogliendoli in categorie tipiche. Suggerimenti: cerca con Google, per esempio, “error message guidelines” e immagini con parole chiave “error message”.
2. Donald Norman, nel suo libro La caffettiera del masochista, classifica i lapsus in varie tipologie. Dopo aver letto questa classificazione, trova un esempio di ciascuna tipologia di lapsus nell’uso dei programmi che usi abitualmente con il tuo personal computer.
3. Esamina le modalità di prevenzione e di gestione degli errori dell’utente in tre siti di commercio elettronico appartenenti allo stesso settore di mercato, e individuane pregi e difetti. Quale dei tre siti ha il miglior trattamento degli errori? Motiva dettagliatamente la tua risposta.